Another old paper has been added to the collection of reproducible papers:

March 14, 2008 Documentation No comments
Another old paper has been added to the collection of reproducible papers:
March 14, 2008 Celebration No comments
We are already well into 2008 — and could this year pass without a Madagascar Event?
Of course not!
A coding sprint is coming at full speed, towards us!
Madagascar developers are invited to congregate during May 23-27 in beautiful Golden, Colorado, for the
2008 MADAGASCAR IMPLEMENTATION WORKSHOP:
TOWARDS FULL AUTOMATION AND BETTER ROBUSTNESS
Yes, this is right. Instead of dozing in a dark room listening to others talk, we will actually write code together! We will give Madagascar a real push towards maturity. All necessary info, and more, can be found on the wiki page of the event. See you in Golden!
February 25, 2008 Celebration No comments
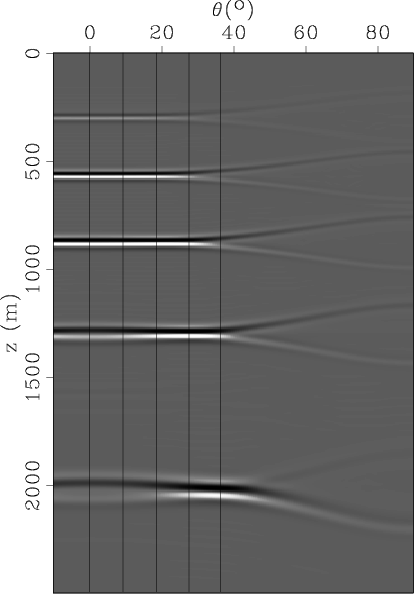
The first constraint to observe when dealing with wide/full-azimuth data is its sheer volume (tens of Terabytes). Data manipulation becomes the bottleneck procedure that the programmer must pay attention to. In practice, this means that data sorting, FFT-ing, axis reversing and transposing are not trivial operations any longer and their number must be minimized. As a consequence, it will often be preferrable to re-write a particular processing tool to apply to the current form the data is in, instead of re-shaping the data to fit to an existing algorithm. Thankfully, such re-writing would usually only involve re-ordering loops and adding or removing FFTs.
The circumstances above mean that clean, documented, maintainable codes, that can be modified in a pinch without adding bugs are a must when working with wide-azimuth data. The collaboration among geographically separated programmers that do not know each other and do not share a common cultural background necessarily imposes these qualities on open-source software. Considerable discipline is needed by in-house programmers in order to get to the same result. Companies which use open-source software that has the above-described qualities will be able to have a faster wide/full azimuth project turnaround. Conversely, the emergence of wide/full-azimuth data acquisition represents a great opportunity for community-based geophysical open-source software!
Many of the data processing operations are data-parallel: different traces, shot gathers, frequency slices, etc. can be processed independently. Madagascar provides several mechanisms for handling this type of embarrassingly parallel applications on computers with multiple processors.
OpenMP is a standard framework for parallel applications on shared-memory systems. It is supported by the latest versions of GCC and by some other compilers.
To run a data-parallel processing task like
on a shared-memory computer with multiple processors (such as a multi-core PC), try sfomp, as follows:.
sfomp splits the input along the slowest axis (presumed to be data-parallel) and runs it through parallel threads. The number of threads is set by the OMP_NUM_THREADS environmental variable or (by default) by the number of available CPUs.
MPI (Message-Passing Interface) is a standard framework for parallel processing on different computer architectures including distributed-memory systems. Several MPI implementations (such as MPICH) are available.
To parallelize a task using MPI, try sfmpi, as follows:
where the argument after -np specifies the number of processors involved. sfmpi will use this number to split the input along the slowest axis (presumed to be data-parallel) and to run it through parallel threads.
Note: Some MPI implementations do not support system calls implemented in sfmpi and therefore will not support this option.
It is possible to combine the advantages of shared-memory and distributed-memory architectures by using OpenMP and MPI together.
will distribute the job on 32 nodes and split it again on each node using shared-memory threads.
If you process data using SCons, another option is available. Change
in your SConstruct file to
where the optional split= parameter contains the axis that needs to be split and the size of this axis. Then run something like
The -j options instructs SCons to run in parallel creating 8 threads, while the CLUSTER= option supplies it with the list of nodes to use and the number of processes to involve for each node. The output may look like
< inp.rsf /RSFROOT/bin/sfwindow n3=42 f3=0 squeeze=n > inp__0.rsf < inp.rsf /RSFROOT/bin/sfwindow n3=42 f3=42 squeeze=n > inp__1.rsf /usr/bin/ssh node1.utexas.edu "cd /home/test ; /bin/env < inp.rsf /RSFROOT/bin/sfwindow n3=42 f3=84 squeeze=n > inp__2.rsf " < inp.rsf /RSFROOT/bin/sfwindow n3=42 f3=126 squeeze=n > inp__3.rsf < inp.rsf /RSFROOT/bin/sfwindow n3=42 f3=168 squeeze=n > inp__4.rsf /usr/bin/ssh node1.utexas.edu "cd /home/test ; /bin/env < inp.rsf /RSFROOT/bin/sfwindow f3=210 squeeze=n > inp__5.rsf " < inp__0.rsf /RSFROOT/bin/sfradon p0=0 np=100 dp=0.01 > out__0.rsf /usr/bin/ssh node1.utexas.edu "cd /home/test ; /bin/env < inp__1.rsf /RSFROOT/bin/sfradon p0=0 np=100 dp=0.01 > out__1.rsf " < inp__3.rsf /RSFROOT/bin/sfradon p0=0 np=100 dp=0.01 > out__3.rsf /usr/bin/ssh node1.utexas.edu "cd /home/test ; < spike__4.rsf /RSFROOT/bin/sfradon p0=0 np=100 dp=0.01 > out__4.rsf " < inp__2.rsf /RSFROOT/bin/sfradon p0=0 np=100 dp=0.01 > out__2.rsf < inp__5.rsf /RSFROOT/bin/sfradon p0=0 np=100 dp=0.01 > out__5.rsf < out__0.rsf /RSFROOT/bin/sfcat axis=3 out__1.rsf out__2.rsf out__3.rsf out__4.rsf out__5.rsf > out.rsf
Splitting the input with sfwindow and putting the output back together with sfcat are immediately apparent. The advantage of the SCons-based approach (in addition to documentation and reproducible experiments) is fault tollerance: If one of the nodes dies during the process, one should be able to restart the computation without recreating parts that are already computed.
All these options will continue to evolve and improve with further testing. Please report your experiences and suggestions.
December 24, 2007 Documentation No comments
Another old paper has been added to the collection of reproducible papers:

October 27, 2007 Uncategorized 10 comments
The collection of fonts in Vplot is small and goes back to so-called “Hershey fonts” (created originally by Dr. A.V. Hershey at the U. S. National Bureau of Standards).
You can use \F# directives to switch between different fonts.
In general, there are two sorts of escape sequences, those that take an argument and those that do not. Here is a complete list of escape sequences that do not take an argument:
The following escape sequences take an integer argument immediately after, with a required space after the integer to delineate the end. This space is not printed.
The following example is from rsf/rsf/sfgraph:
The line to create this title is
.
You can find a set of tests for different fonts in pens/tests:
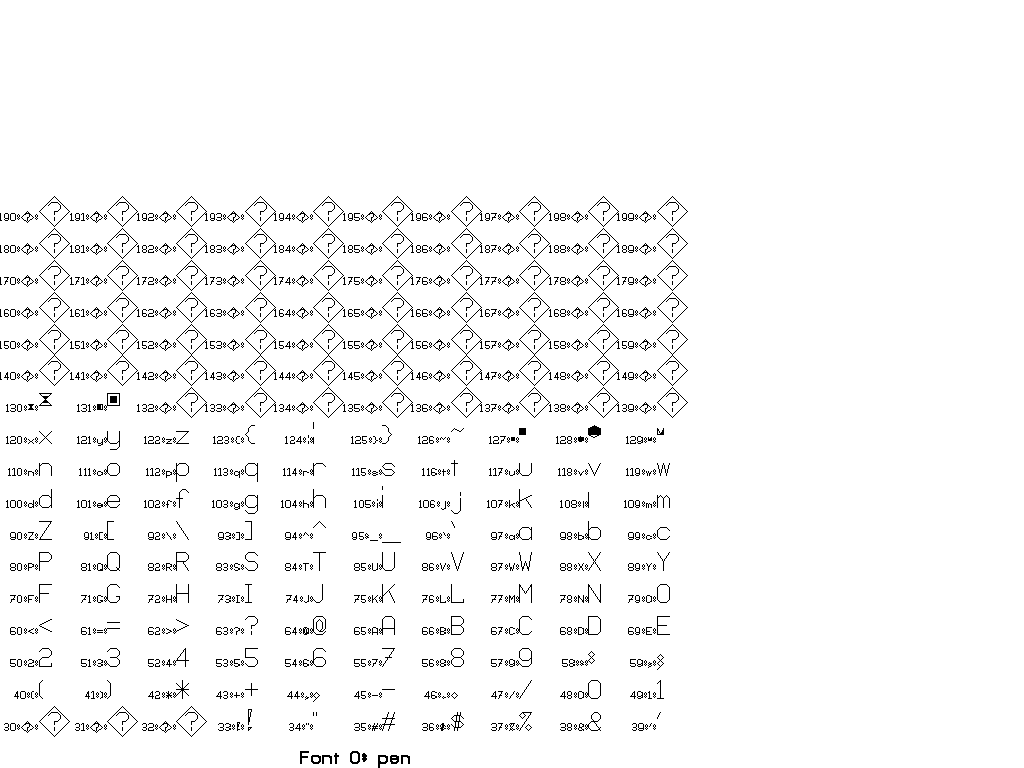
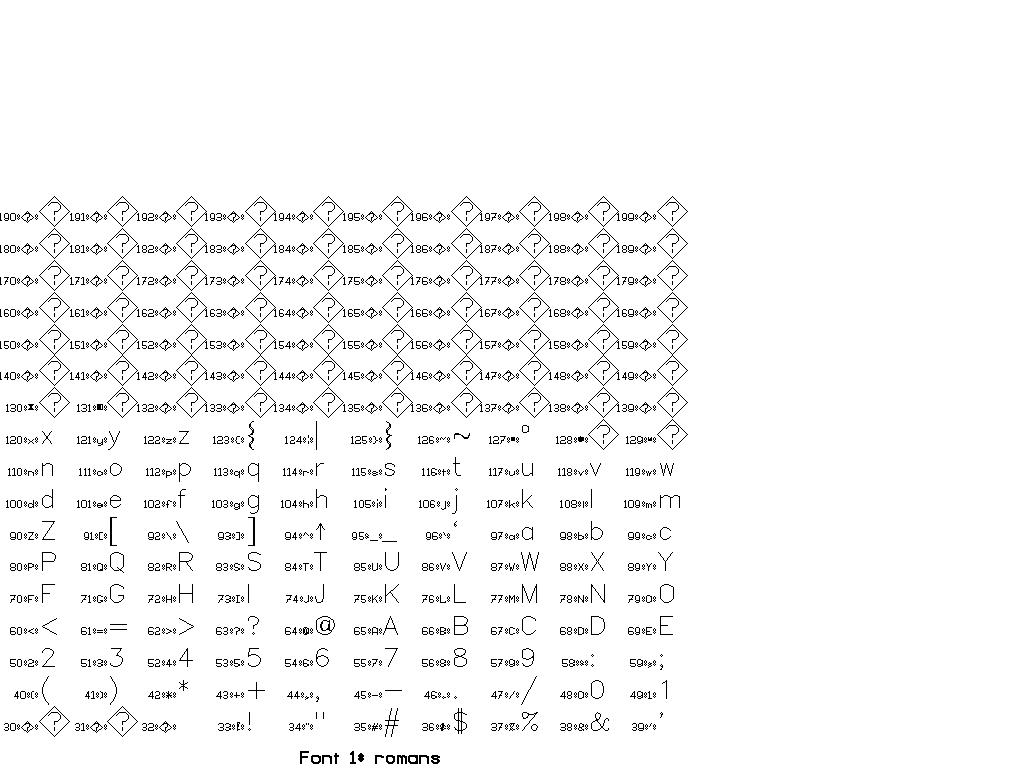
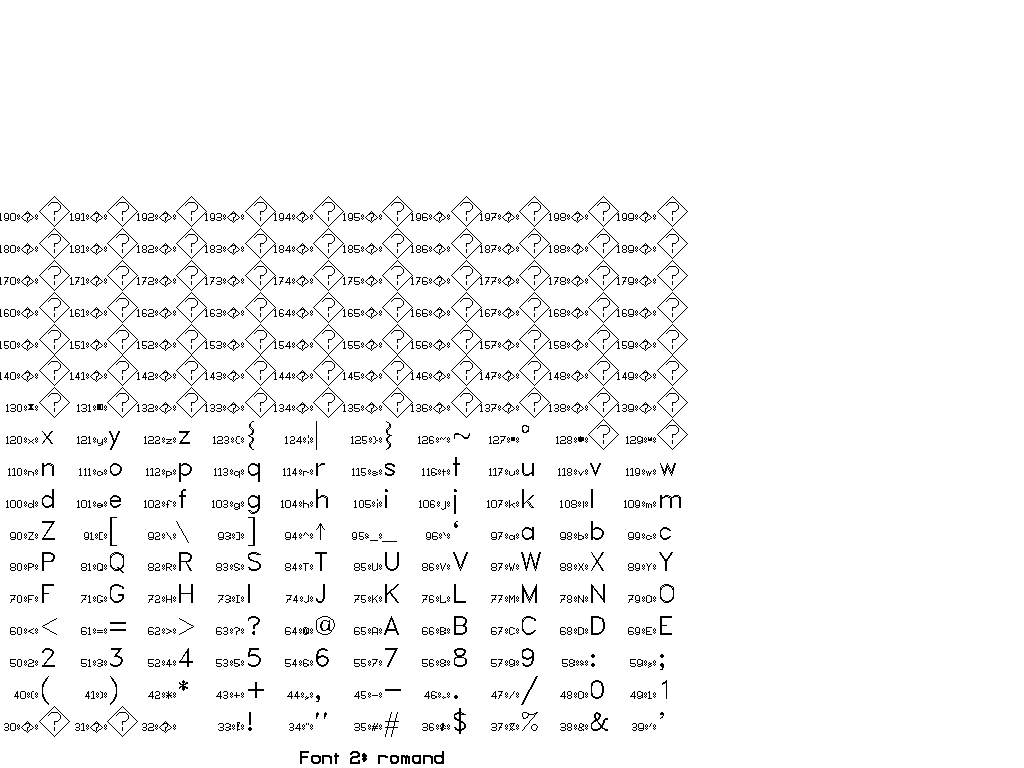
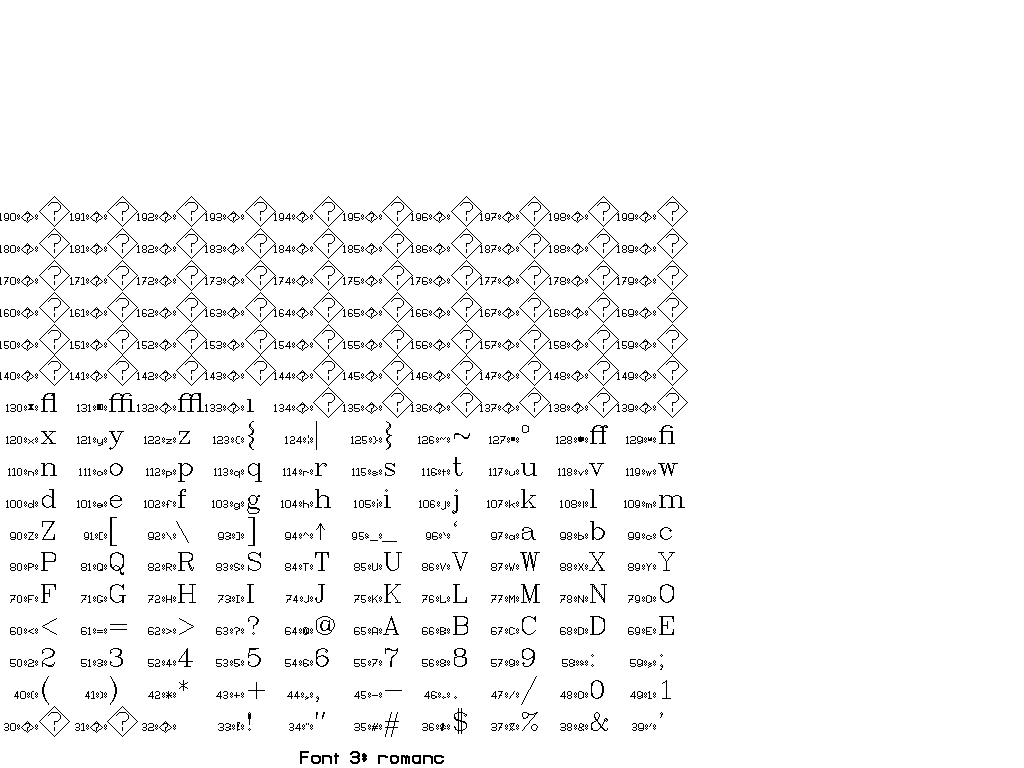
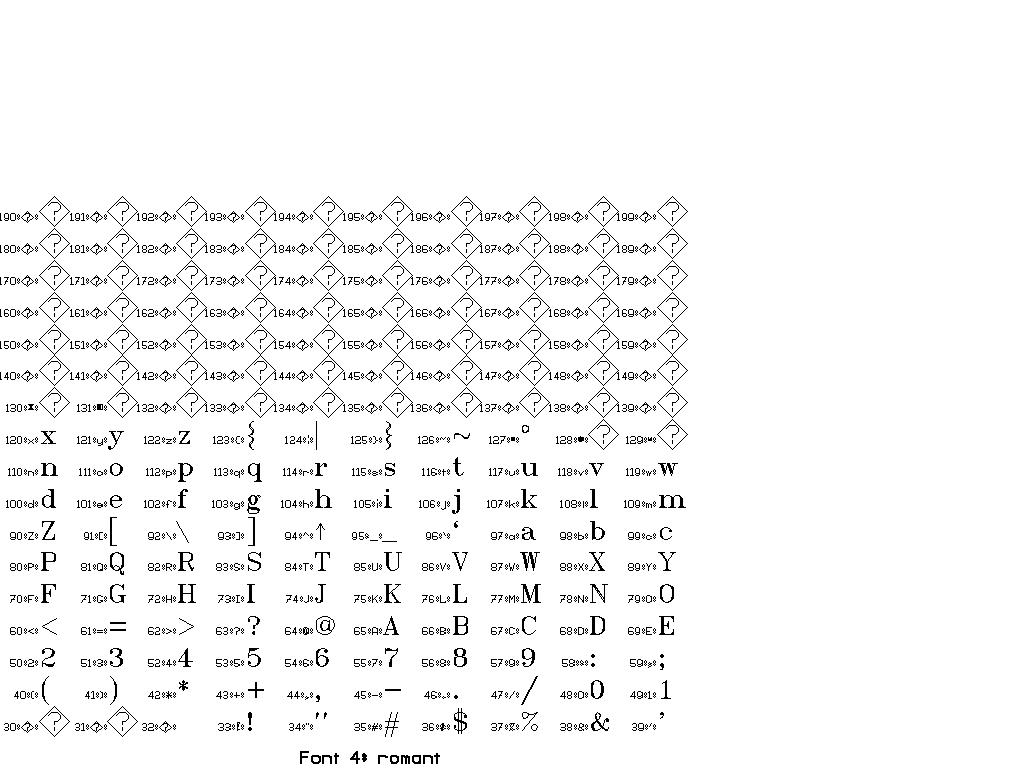
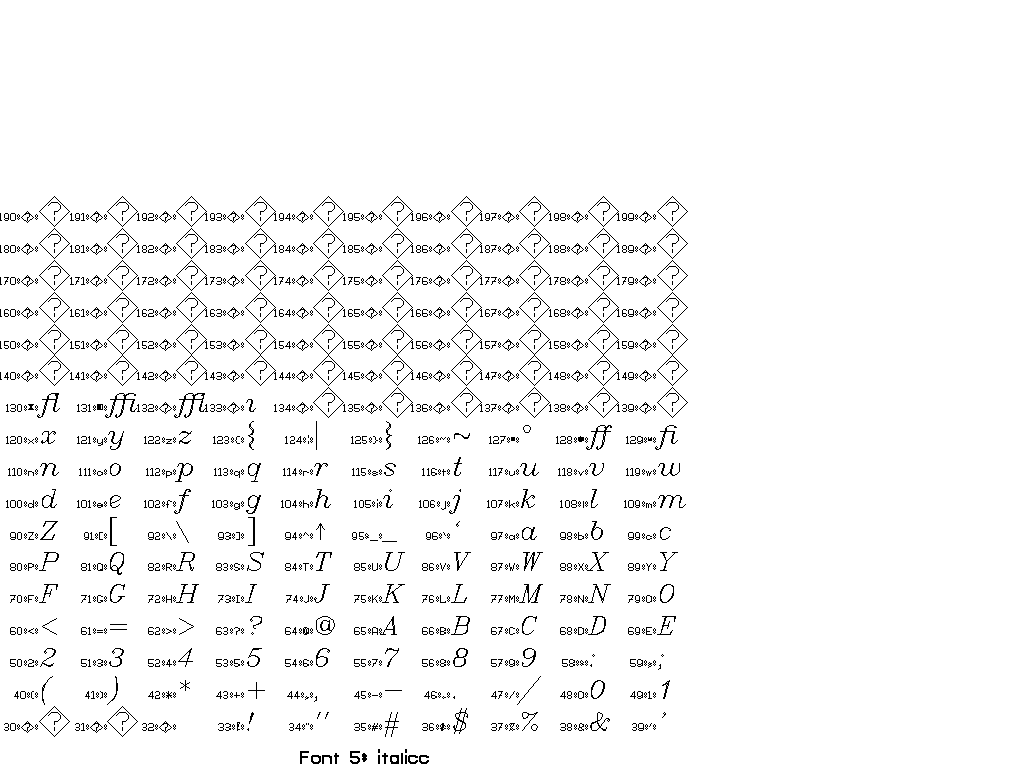
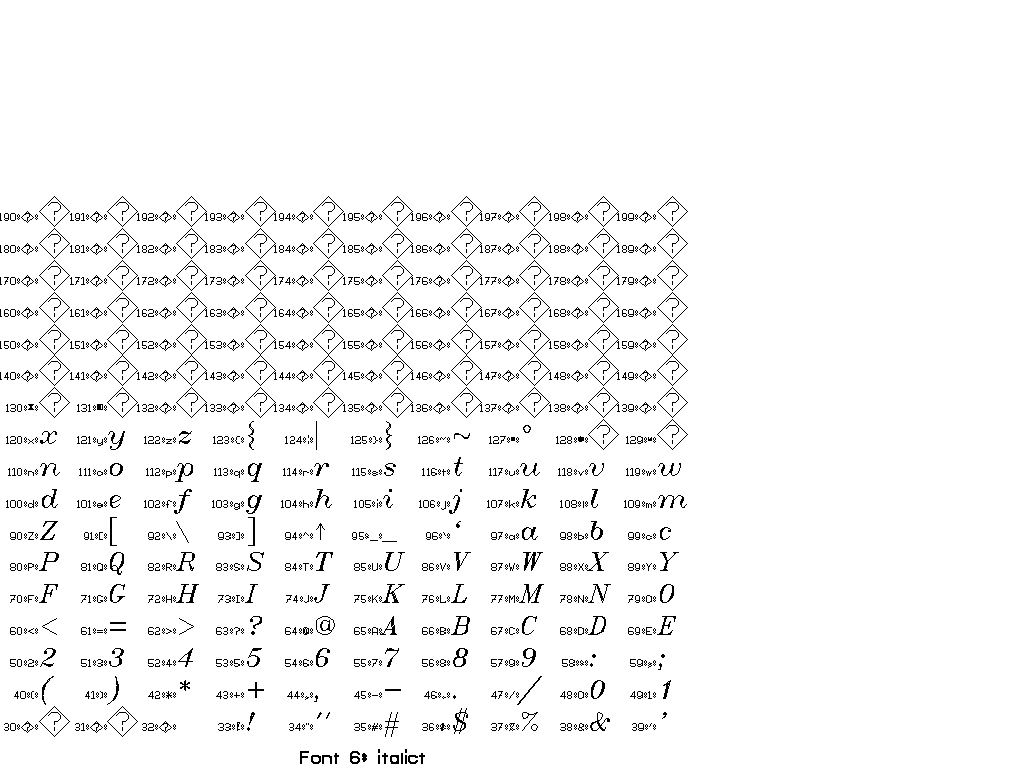

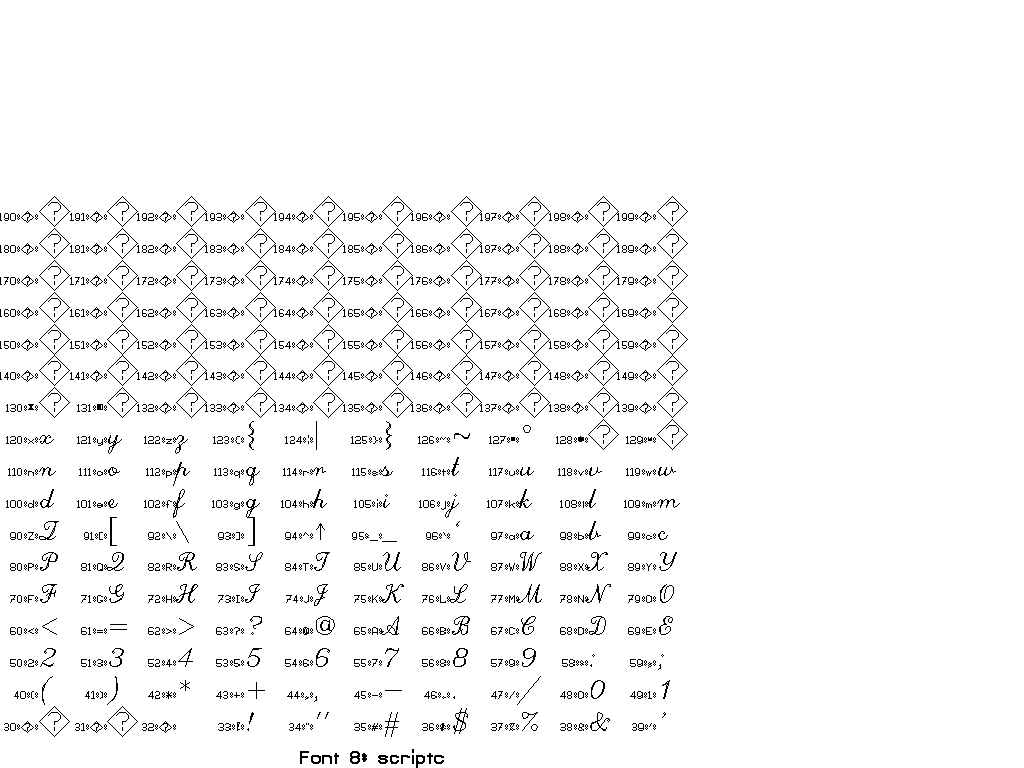

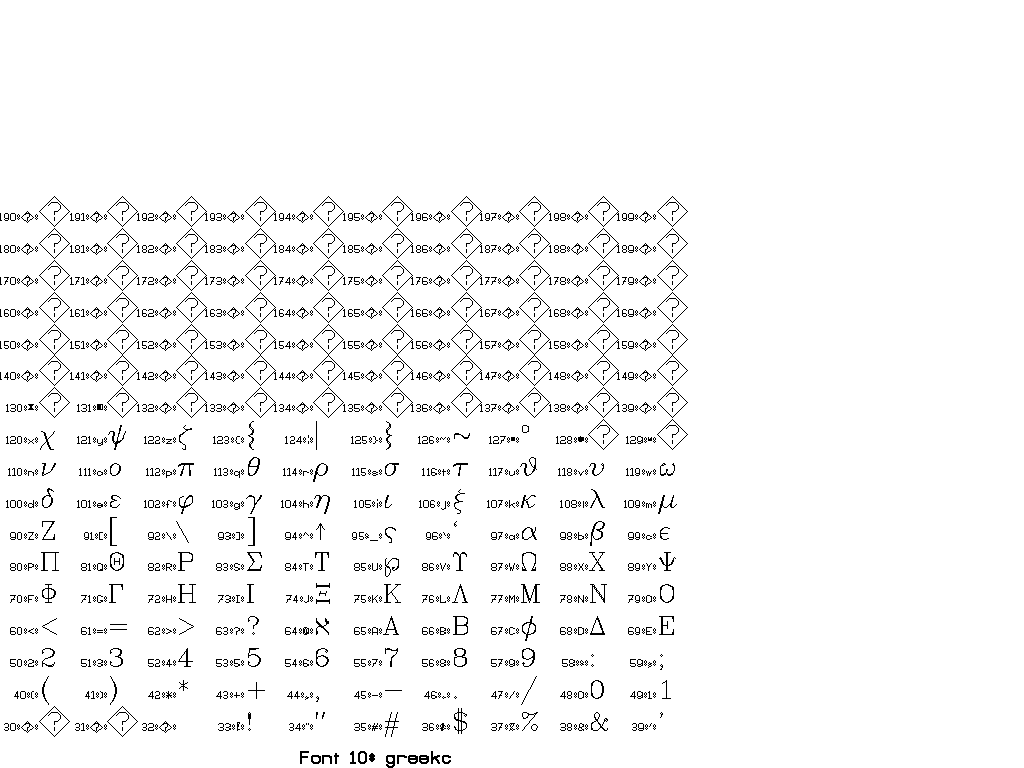
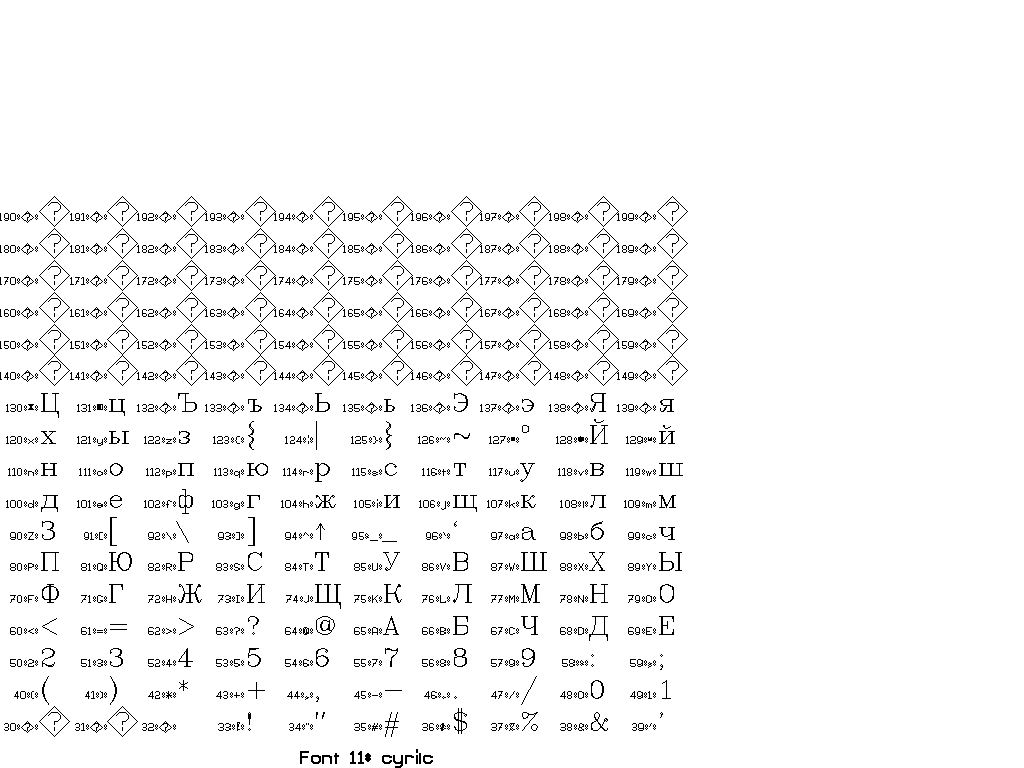

Thanks to Joe Dellinger for help with this answer! For more information, see his presentation on Vplot and vplotttext.m.
October 14, 2007 Celebration No comments
New stable version is released.
The previous stable versions have been downloaded more than 1,500 times in 16 months. In the same period of time, the development version experienced more than 3,300 read transactions, more than 1,100 write transactions, and more than 7,400 file updates (statistics from SourceForge).
October 14, 2007 Systems No comments
madagascar has been successfully installed on HP-UX and SGI Irix using native compilers.
October 7, 2007 Documentation No comments
A new paper has been added to the collection of reproducible papers:
October 7, 2007 Documentation No comments
A new paper has been added to the collection of reproducible papers: