Coming from a completely different field (computational linguistics), Ted Pedersen argues that
See also slides (and listen to audio) from Ted’s keynote presentation at the 2009 NACCL conference.
August 17, 2009 Systems No comments
July 12, 2009 Systems No comments
James Quirk provides an example of running Madagascar from a PDF file using AMRITA. To try it out, you need to install AMRITA first.
June 21, 2009 Systems No comments
Having a known maximum source code line length is a very useful thing. This way, code fragments can be automatically included into other kinds of media without breaking formatting rules. Coding standards for most large, established software projects (either open-source or proprietary) explicitly mention line length.
However, what is a good line length limit? The 80-character limit is very widespread, but how does it compare to what peoples have naturally been writing? To find out, I used a little Python script (adm/line_len_hist.py) to count line lengths for various types of files in the Madagascar code base. Pictures follow below, for all source code files (including SConstruct files) and the most prevalent file types. To my surprise, the 80-character threshold is quite relevant, and it might be worth having it as an explicit coding style suggestion on the wiki, to help new contributors!




January 30, 2009 Systems No comments
Madagascar flow builder in OpendTect (picture courtesy of Bert Bril)
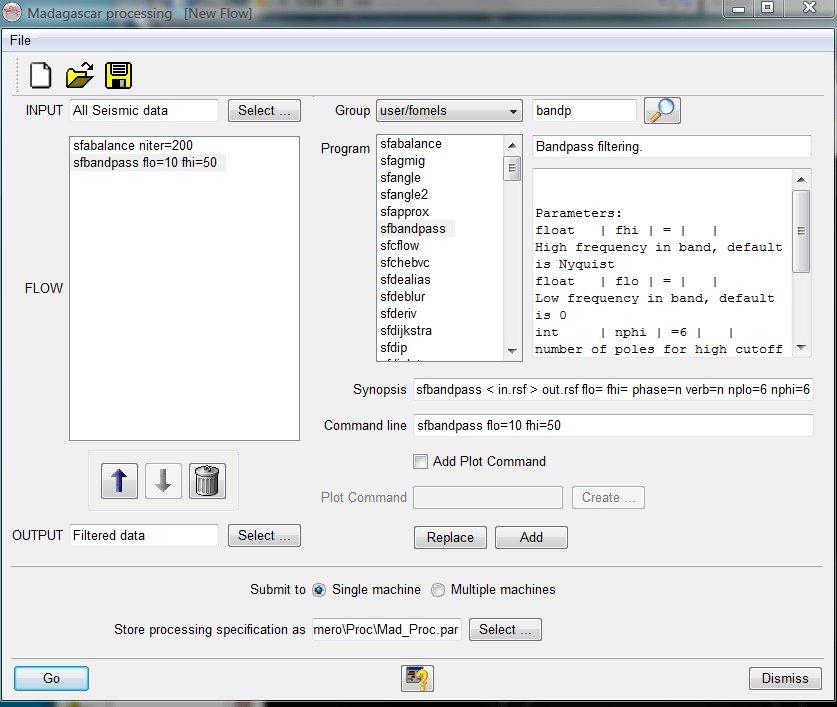
January 10, 2009 Systems No comments
Nice article in the New York Times about the R project. R and Bioconductor are great examples of successful open-source scientific communities, dedicated to free software and computational reproducibility. We can use them as models and possibly look for ways to integrate.
August 6, 2008 Systems No comments
In the light of the recent discussion on extending the Python interface to Madagascar, I would like to inform those of you who did not know already about the public release of SLIMpy: SLIM-UBC’s Python interface to out-of-core seismic data processing.
SLIMpy is a Python interface that exposes the functionality of seismic data processing packages, such as MADAGASCAR, through operator overloading. SLIMpy provides a concrete coordinate-free implementation of classes for out-of-core linear (implicit matrix-vector), and element-wise operations, including calculation of norms and other basic vector operations. The library is intended to provide the user with an abstract scripting language to program iterative algorithms from numerical linear algebra. These algorithms require repeated evaluation of operators that were initially designed to be run as part of batch-oriented processing flows. The current implementation supports a plugin for Madagascar’s out-of-core UNIX pipe-based applications and is extenable to pipe-based collections of programs such as Seismic Un*x, SEPLib, and FreeUSP. To optimize performance, SLIMpy uses an Abstract Syntax Tree that parses the algorithm and optimizes the pipes.
The main features of SLIMpy include:
– Powerful interpreted programming language (Python)
– Syntax (through overloading) close to pseudo-code for numerical linear algebra
– Abstract Syntax Tree analyzer/optimizer (including command rearrangement form improved performance)
– Concrete linear operator and vector classes, including dottests, domain-range and type checks
– Elementwise reduction-transformation operations (norms, elementary math)
– Compounded linear operators
– Augmented linear operators and vector classes
– Plugin mechanism for Unix pipe-based collections of (seismic) data processing programs
– Parallel execution of reduction/transformation operations
– Parallel execution of embarrassingly parallel linear operators (block diagonal)
– Integration with SCons
– Automatic cleanup of temporary datafiles (garbage collection)
– In-code documentation through Doxygen
SLIMpy is an academic research code that we share with the community through this alpha release. By making SLIMpy available as open source, we hope to create an active community to further develop this software.
SLIMpy is released under GNU Lesser General Public License, and it is available for download from SVN repositories:
– the core packages from https://wave.eos.ubc.ca/Public/Public.Software.SLIMpy/
– the contributions from https://wave.eos.ubc.ca/Public/Public.Software.SLIMpy-contrib/
Additional documentation and tutorials can be found at
– SLIMpy’s documentation http://slim.eos.ubc.ca/SLIMpy/
– SLIMpy’s tutorial http://slim.eos.ubc.ca/SLIMpy/exampleset1.html
Through this release, we hope that SLIMpy can grow into a widely-used Library, supplementing the functionality of currently available processing-flow oriented (seismic) software packages. Please, use SLIMpy-user (http://slim.eos.ubc.ca/mailman/listinfo/slimpy-user) mailing list to report concerns and exchange the ideas. Those of you, who wish to contribute to development, please, subscribe to SLIMpy-devel (http://slim.eos.ubc.ca/mailman/listinfo/slimpy-devel).
Most of the credit for developing SLIMpy goes to Sean Ross-Ross of the SLIM group.
August 3, 2008 Systems No comments
Work is under way on extending the Python interface to Madagascar. With new tools, you should be able to use an interactive Python session rather than a Unix shell to run Madagascar modules. Here are some examples:
import m8r as sf
import numpy, pylab
f = sf.spike(n1=1000,k1=300)[0]
# sf.spike is an operator
# f is an RSF file object
f.attr()
# Inspect the file with sfattr
b = sf.bandpass(fhi=2,phase=1)[f]
# Now f is filtered through sfbandpass
c = sf.spike(n1=1000,k1=300).bandpass(fhi=2,phase=1)[0]
# c is equivalent to b but created with a pipe
g = c.wiggle(clip=0.02,title='Welcome to Madagascar')
# g is a Vplot file object
g.show()
# Display it on the screen
d = b - c
# Elementary arithmetic operations on files are defined
g = g + d.wiggle(wanttitle=False)
# So are operations on plots
g.show()
# This shows a movie
pylab.show(pylab.plot(b))
c = numpy.clip(b,0,0.01)
# RSF file objects can be passed to pylab or numpy
c.attr()
s = c[300:310]
print s
# Taking a slice outputs a numpy array
c = sf.clip(clip=0.01)[b]
c.attr()
# Alternatively, apply sfclip
For doing reproducible research, one can also use the new syntax inside SConstruct files, as follows:
from rsf.proj import *
import m8r as sf
Flow('filter',None,sf.spike(n1=1000,k1=300).bandpass(fhi=2,phase=1))
Result('filter',sf.wiggle(clip=0.02,title='Welcome to Madagascar'))
End()
See also a 4-line dot-product test and 20-line conjugate-gradient algorithm.
The picture shows a screenshot of an interactive session in a SAGE web-based notebook
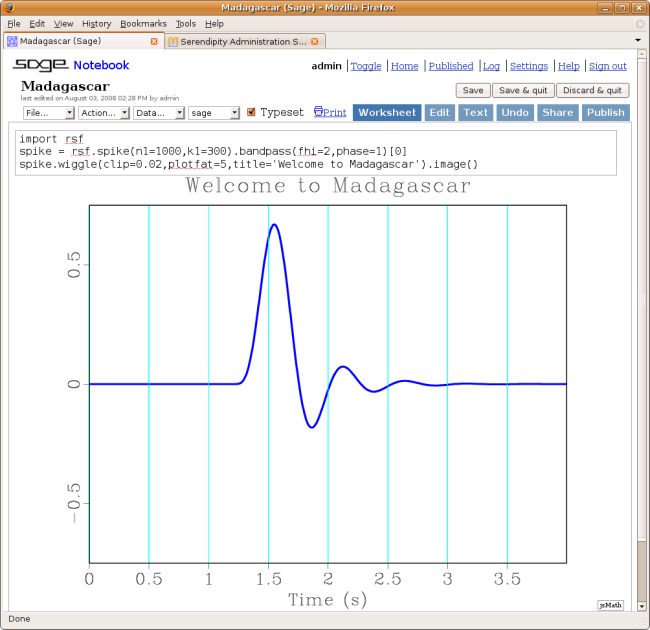
July 15, 2008 Systems No comments
The latest version of OpendTect includes a Madagascar processing flow builder. The screenshot is contributed by Hesam Kazemeini.
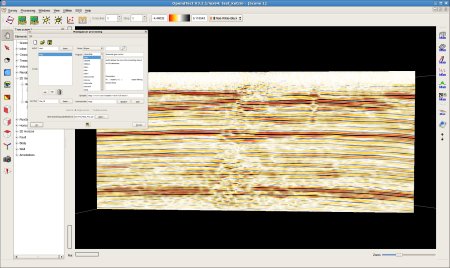
October 14, 2007 Systems No comments
madagascar has been successfully installed on HP-UX and SGI Irix using native compilers.
May 28, 2007 Systems No comments
Since infinite numbers of monkeys hitting keys on typewritters for an infinite amount of time are not usually available for employment, researchers do not proceed at random, but come up instead with a hypothesis, followed by experiments. Ideas may be stimulated by close acquaintance with the subjects and tools of the experiment, but by the very nature of things theory proceeds in time before the experiment, for else one would not know how to design that experiment.
Many theories are sequences of logical statements that can be divided into a number of discrete falsifiable fragments. One option is to postpone experiments until the whole theory is complete, with proofs of convergence, existence, and whatnot. It may be reasonable to argue that until the whole theory is formally complete in all its majesty, one cannot properly perceive the significance of the fragment in context, and experiments need to be designed with the whole theory in mind.
However, a researcher that would proceed in the forementioned way would only discover that he is significantly less productive than his peers! What happened??
Well, his peers probably did something else. Namely they tried to test individual, even incomplete pieces of the theory. If the experiment does not work, they will know quite early, and find workarounds or just give up the dead end and try another hypothesis — until finally they hit on something that works. During all this time that the theory-minded fellow has been pouring equations for a single theory, without knowing whether the inevitable approximations will not doom its application to real data. On top of that, his fellows had more contact with real data and more inspiration for their other theories!
The strategy of his peers resembles quite closely the “release early, release often” saying of the open-source world. It resembles Agile development strategies, in contrast to the the Waterfall model.
The “implement early, implement often” approach also brings to mind a saying from a completely different field: the popular “Cut the losers early, let the winners run” advice to investors. Researchers are much like investors, just that they invest time instead of money. This analogy is not merely interesting: it is useful. A lot of statistics were done about expected returns for investors, which are described better by Pareto distributions/power laws (80/20 rule, etc) than by symmetric Gaussian pdfs, so culling “losers” when they reach a threshold but keeping “winners” biases the expectation towards winners. It is quite straightforward (but tedious) to map investor gains to number of references in peer-reviewed journals, count references and interview researchers about the number of hypotheses tried and discarded, and map the finance-domain portofolio statistical work to the research-domain. Venture capital firms large enough, who need to evaluate and invest in researchers, may have already done that.
What is necessary in order to “implement early, implement often”? Most important, software should be quite usable (being learnable helps as well; yes, these are different things). In the case of a development platform, like Madagascar, where users may freely adapt existing programs, code needs to be clean and easy to understand as well; for this kind of software, code readability and implementation descriptions are more than good practice for future maintenance, but productivity enhancers for current users as well! Madagascar, known for these attributes, is already up to a good start. Bottom line: usability multiplies productivity much more than comes to mind at first thought (i.e. time saved in not looking up things), since hard-to-use software decreases the probability of the researcher putting an idea to the test at all, and instead results in him postponing the moment of coding, without realising the aggregate productivity loss!
In conclusion: let us get to know Madagascar well, implement early, and implement often!