The CUDA programming model assumes that both the host and the device maintain their own separate memory spaces in DRAM, referred to as host memory and device memory, respectively. Before we introduce the details about the architecture of the cu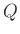 -RTM code package, we need to clarify the variable definition and figure out which variables need to be transferred between host memory and device memory. Table 1 presents some important variables allocated on host and device, which fall into three memory types: pageable host memory, page-locked host memory, and global device memory. The philosophy of choosing host variable types is that variables to be frequently copied between host and device, such as
-RTM code package, we need to clarify the variable definition and figure out which variables need to be transferred between host memory and device memory. Table 1 presents some important variables allocated on host and device, which fall into three memory types: pageable host memory, page-locked host memory, and global device memory. The philosophy of choosing host variable types is that variables to be frequently copied between host and device, such as
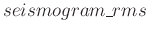 and
and
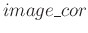 , are allocated in page-locked host memory, whereas the rest of the host variables are allocated as regular pageable host memory. Because copies between page-locked host memory and device memory can be performed concurrently with kernel execution, data transfer can be overlapped during kernel execution leading to a more efficient streaming execution on cluster nodes with multiple GPUs.
, are allocated in page-locked host memory, whereas the rest of the host variables are allocated as regular pageable host memory. Because copies between page-locked host memory and device memory can be performed concurrently with kernel execution, data transfer can be overlapped during kernel execution leading to a more efficient streaming execution on cluster nodes with multiple GPUs.
struct MultiGPU contains page-locked host variables and global device variables (with 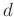 as a prefix) on every stream. From this struct variable, we can estimate the total device memory usage before execution and ensure that the memory usage will not exceed the memory limit. CUDA threads (kernel functions) execute on a physically separate device (GPUs), whereas the rest of the C program executes on the host (CPUs). Therefore, a program manages the global memory accessible to kernels through calls to the CUDA runtime such as device memory allocation cuda_Device_malloc(
as a prefix) on every stream. From this struct variable, we can estimate the total device memory usage before execution and ensure that the memory usage will not exceed the memory limit. CUDA threads (kernel functions) execute on a physically separate device (GPUs), whereas the rest of the C program executes on the host (CPUs). Therefore, a program manages the global memory accessible to kernels through calls to the CUDA runtime such as device memory allocation cuda_Device_malloc( ), deallocation cuda_Device_free(), and initialization cuda_Host_initialization() as well as data transfer between host and device memory.
), deallocation cuda_Device_free(), and initialization cuda_Host_initialization() as well as data transfer between host and device memory.

|
|---|
Fig1
Figure 1. The architecture of the cuQ-RTM code package.
|
|---|
![[pdf]](icons/pdf.png) ![[png]](icons/viewmag.png) ![[scons]](icons/configure.png)
|
|---|
Table 1:
Some important variables allocated on host and device.
| |
Memory type |
|
Variables |
| <#4997#> |
pageable |
|
| | ricker, vp, Qp, Gamma, t_cp |
|
| | kfilter, kstabilization |
|
| | Final_image_cor, Final_image_cor |
|
|
| |
page-locked |
| | cudaMallocHost() |
|
| | cudaFreeHost() |
|
|
| Device |
global |
|
| | d_ricker, d_vp, d_Gamma, d_t_cp, d_u_cp |
|
| | d_u0, d_u1,d_u2, d_seimogram_rms |
|
| | d_image_cor, d_image_nor |
|
| | d_uk, d_Lap_uk, d_amp_uk, d_pha_uk |
|
| | d_borders_up, d_u2_final0, d_u2_final1 |
|
|
2020-04-03