 |
 |
 |
 | Double sparsity dictionary for seismic noise attenuation |  |
![[pdf]](icons/pdf.png) |
Next: Solving the analysis model
Up: Theory
Previous: Double sparsity dictionary
Provided that the learning-based dictionary is a tight frame such that
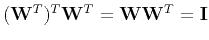 ,
DSD can be learned by considering the following problem:
,
DSD can be learned by considering the following problem:
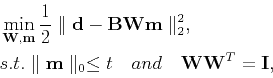 |
(3) |
where 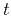 denotes the sparsity constrained coefficient.
denotes the sparsity constrained coefficient.
Equation 3 can be solved alternatively by minimizing
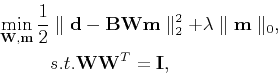 |
(4) |
where 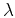 denotes the damping factor, which is connected with the sparsity constrained coefficient
. Equation 4 is called synthesis model for DSD.
denotes the damping factor, which is connected with the sparsity constrained coefficient
. Equation 4 is called synthesis model for DSD.
Assuming the base dictionary
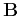 is invertible, the synthesis-based DSD model as shown in equation 3 is equivalent to:
is invertible, the synthesis-based DSD model as shown in equation 3 is equivalent to:
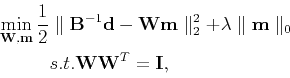 |
(5) |
where
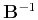 denotes the forward base transform. Equation 5 suggests that DSD can also be learned in the model domain of the multi-scale decomposition operator
instead of in the data domain. Equation 5 is called analysis model for DSD.
denotes the forward base transform. Equation 5 suggests that DSD can also be learned in the model domain of the multi-scale decomposition operator
instead of in the data domain. Equation 5 is called analysis model for DSD.
The synthesis model (equation 4) offers more flexibility for learning DSD because there are many sparsity-promoting transforms that are not exactly invertible. The analysis model, on the other hand, offers more convenience for constructing DSD when an invertible sparsity-promoting
base transform is available.
|
|
|
|
| Double sparsity dictionary for seismic noise attenuation | |
|
Next: Solving the analysis model
Up: Theory
Previous: Double sparsity dictionary
2016-02-27