|
|
|
|
Shortest path ray tracing on parallel GPU devices |
It is performed a test to compare the velocities of GPU
parallel and CPU sequential shortest path ray tracing
algorithms with different model sizes and different
neighborhood radii.
The sequential and parallel versions were executed in
an intel![]() icoreTM i7 CPU
equipped with a nvidia
icoreTM i7 CPU
equipped with a nvidia![]() geforce
geforce![]() gt
650m GPU. Although it is not a high-end GPU device it
can be useful to show the performance of the parallel
ray tracer and better performance is expected from more
advanced GPUs. This GPU has the following relevant specifications:
gt
650m GPU. Although it is not a high-end GPU device it
can be useful to show the performance of the parallel
ray tracer and better performance is expected from more
advanced GPUs. This GPU has the following relevant specifications:
There were built ![]() velocity models with dimensions
ranging from
velocity models with dimensions
ranging from ![]() vertices to
vertices to
![]() vertices to test the GPU parallel program performance. All
models were a simple vertical gradient with
vertices to test the GPU parallel program performance. All
models were a simple vertical gradient with ![]() on the
top and
on the
top and ![]() on the bottom.
on the bottom.
The GPU function kernels were made for a block size of
![]() threads to meet the maximum number of threads
per block and the maximum shared memory per block. The measured
times account for all GPU operations: data transfers to
and from device, weight precalculation and ray tracing.
threads to meet the maximum number of threads
per block and the maximum shared memory per block. The measured
times account for all GPU operations: data transfers to
and from device, weight precalculation and ray tracing.
The sequential version of the shortest path ray tracer was also tested using the same set of velocity models to provide a point of comparison. This sequential version was implemented with the standard library priority queue that provides a fast implementation of this data structure that dominates the velocity of this algorithm. Both ray tracers, sequential and parallel, were compiled with -O4 optimization flag.
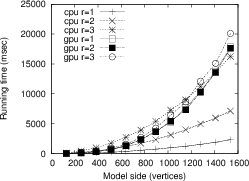
In Figure 7 are shown the time results
for three neighborhood radii: ![]() and
and ![]() . The CPU
version outperforms the parallel one in the first two
radii and is almost as good in the third. The reason is
that in calculations with low radius values there
are not enough operations to keep the GPU busy while waiting
for data transfers from global to shared memory.
. The CPU
version outperforms the parallel one in the first two
radii and is almost as good in the third. The reason is
that in calculations with low radius values there
are not enough operations to keep the GPU busy while waiting
for data transfers from global to shared memory.
|
|---|
|
result1
Figure 7. CPU vs. GPU for three neighborhood radius: |
|
|
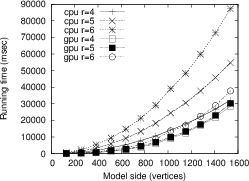
Figure 8 displays the time results
for other three neighborhood radii: ![]() and
and ![]() .
In these cases, the parallel implementation is faster
than the sequential one, with a speedup factor between
.
In these cases, the parallel implementation is faster
than the sequential one, with a speedup factor between
![]() and
and ![]() for the highest radius. In these cases the
high number of operations per thread was enough to
hide the latency of global memory. Despite the low capacity
of the GPU device used in the test, this is a significant
improvement over the sequential solution. More powerful
GPU devices can deliver better improvements.
for the highest radius. In these cases the
high number of operations per thread was enough to
hide the latency of global memory. Despite the low capacity
of the GPU device used in the test, this is a significant
improvement over the sequential solution. More powerful
GPU devices can deliver better improvements.
One important thing to consider involves the memory requirements.
The most expensive piece of data is the weight array that
has
![]() elements for each model vertex. This imposes
a very serious restriction to the model size because of the limited
amount of memory in the GPU device. This can be amelioriated
with a swapping scheme that loads this array by fragments or
by using various GPU devices at the same time. Both possibilities
need further experimentation. The possibility of calculating
this array on the fly at each iteration is out of the question
because it is very time consuming. On the other side,
the weight precalculation can be better amortized if varius ray
tracings with different sources are going to be performed on
the same velocity model, so only one precalculation is needed
for all of them.
elements for each model vertex. This imposes
a very serious restriction to the model size because of the limited
amount of memory in the GPU device. This can be amelioriated
with a swapping scheme that loads this array by fragments or
by using various GPU devices at the same time. Both possibilities
need further experimentation. The possibility of calculating
this array on the fly at each iteration is out of the question
because it is very time consuming. On the other side,
the weight precalculation can be better amortized if varius ray
tracings with different sources are going to be performed on
the same velocity model, so only one precalculation is needed
for all of them.
|
|---|
|
result2
Figure 8. CPU vs. GPU for three neighborhood radius: |
|
|
A mild vertical gradient velocity model is shown in Figure 9.
The velocity of this model varies with depth ![]() :
: ![]() in
in ![]() .
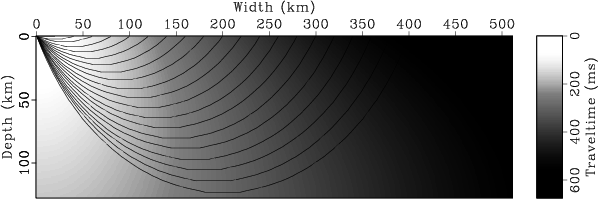
Figure 10 shows a composite image of traveltimes to all
model positions and some selected rays using the GPU raytracer
with size neighbor equal six, in just one run.
.
Figure 10 shows a composite image of traveltimes to all
model positions and some selected rays using the GPU raytracer
with size neighbor equal six, in just one run.

|
|---|
|
grad
Figure 9. Vertical velocity gradient: |
|
|
|
|---|
|
timesrays
Figure 10. Traveltimes to all velocity model positions and some selected rays. Source is at |
|
|
|
|
|
|
Shortest path ray tracing on parallel GPU devices |