|
|
|
|
Shortest path ray tracing on parallel GPU devices |
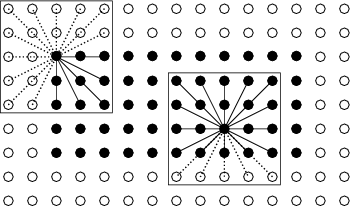
One important thing to avoid in programming parallel algorithms for GPUs is thread divergence. Thread divergence occurs when threads executing concurrently follow different execution paths. This behaviour can not be avoided in the conditional structures (if) of Algorithms 3 and 4. Iteration structures (forall) of Algorithms 1 and 3 can also suffer from thread divergence because threads in charge of vertices near the border of the velocity model have fewer neighbor vertices to process. One possible solution is to complete the neighborhoods of these vertices by extending the velocity model with dummy vertices. The weights between these dummy vertices and the normal ones have sufficiently big values to ensure that they are not going to form part of any shortest ray path. This is shown in Figure 5 where the white vertices have been added to the model and the dotted edges have big weights. Kernels in Algorithms 1 and 3 are still only launched for normal model vertices.
|
|---|
|
extvelmodel
Figure 5. Model extension with dummy vertices to diminish thread divergence. |
|
|
Another improvement is to use the device shared memory with
data that is going to be read multiple times, because this
memory is faster than the global one. Shared
memory is only shared inside groups of threads called blocks.
To take advantage of it the model is divided into rectangular
vertex areas with enough information to be completely and
independently processed by each block. Due to the dependency
of a vertex on its neighbor vertices, these areas should
contain some vertices from adjacent areas, i.e. the rectangular
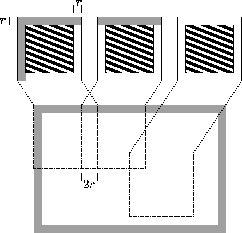
areas overlap. Figure 6 shows a velocity
model and a group of overlapping areas. The stripped zones
are the vertices processed by each block. The nonstripped
border zones are vertices from adjacent areas that are needed
in the current block. This area has a thickness equal to the
neighborhood radius ![]() . Grey areas correspond to the dummy
vertices added before to reduce thread divergence. This approach
is used in Micikevicius (2009) to compute
3D finite differences, but with a different overlapping shape.
. Grey areas correspond to the dummy
vertices added before to reduce thread divergence. This approach
is used in Micikevicius (2009) to compute
3D finite differences, but with a different overlapping shape.
In Algorithm
1 velocity values in array ![]() are read
multiple times, hence that array is a good candidate to be
loaded in shared memory. Before the iteration structure in this
kernel function each
thread reads once from global memory the velocity of its vertex
in array
are read
multiple times, hence that array is a good candidate to be
loaded in shared memory. Before the iteration structure in this
kernel function each
thread reads once from global memory the velocity of its vertex
in array ![]() and stores it in a shared array (this is the
stripped zone in Figure 6). Some threads are
also assigned to copy the overlaping zones of
and stores it in a shared array (this is the
stripped zone in Figure 6). Some threads are
also assigned to copy the overlaping zones of ![]() , i.e, the
nonstripped zone in Figure 6. The same
technique can be applied in Algorithm 3, but with
the array
, i.e, the
nonstripped zone in Figure 6. The same
technique can be applied in Algorithm 3, but with
the array ![]() of traveltimes. There is no need to copy the
weight array
of traveltimes. There is no need to copy the
weight array ![]() to shared memory in this kernel function because
each of its elements is read once.
to shared memory in this kernel function because
each of its elements is read once.
|
|---|
|
overshared
Figure 6. Model partitioning in overlaping areas. |
|
|
|
|
|
|
Shortest path ray tracing on parallel GPU devices |