Next: Need for an invertible
Up: OPPORTUNITIES FOR SMART DIRECTIONS
Previous: OPPORTUNITIES FOR SMART DIRECTIONS
To accelerate convergence of iterative methods, we often change variables.
The model-styling regression
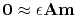 is changed to
is changed to
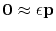 .
Experience shows, however, that the variable
.
Experience shows, however, that the variable 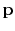 is often more interesting
to look at than the model
is often more interesting
to look at than the model 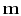 .
Why should a new variable introduced for computational convenience
turn out to have more interpretive value?
There is a little theory explaining why. Begin from
.
Why should a new variable introduced for computational convenience
turn out to have more interpretive value?
There is a little theory explaining why. Begin from
Introduce the preconditioning variable
.
Rewriting as a single regression:
![$\displaystyle \bold 0 \quad\approx\quad \left[ \begin{array}{c} \bold r_d \ \b...
... - \quad \left[ \begin{array}{c} \bold W \bold d \ \bold 0 \end{array} \right]$](img128.png) |
(26) |
The gradient vanishes at the best solution.
To get the gradient,
we put the residual into the adjoint operator.
Thus,
we put the residuals (column vector) in
(26)
into the transpose of the operator in
(26),
the row
 ).
Finally,
replace the
).
Finally,
replace the 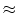 by
by 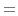 .
Thus,
.
Thus,
The two terms in Equation (27)
are identical but oppositely signed.
These terms represent images in model space.
This image represents the fight between
the data space residual and the model space residual.
You really do want to plot this image.
It shows the battle of
the model wanted by the data
against
our preconceived statistical model expressed by our model styling goal.
That is why the preconditioned variable
is interesting to inspect and interpret.
It is not simply a computational convenience.
It is telling you what you have learned from data
(that someone has recorded at great expense!).
|
The preconditioning variable
is not simply a computational convenience.
This model-space image
tells us where our data contradicts our prior model.
Admire it!
Make a movie of it evolving with iteration.
|
If I were young and energetic like you,
I would write a new basic tool for optimization.
Instead of scanning only the space of the gradient and previous step,
it would scan also over the ``smart'' direction.
Using both directions should offer the benefit of preconditioning
the regularization at early iterations
while offering more assured fitting data at late iterations.
The improved
module for cgstep
would need to solve a 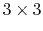 matrix.
I would also be looking for ways to
assure all
matrix.
I would also be looking for ways to
assure all
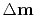 directions
were scaled to have the prior model spectrum and prior energy function of space.
directions
were scaled to have the prior model spectrum and prior energy function of space.
Next: Need for an invertible
Up: OPPORTUNITIES FOR SMART DIRECTIONS
Previous: OPPORTUNITIES FOR SMART DIRECTIONS
2015-05-07