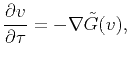|
|
|
|
A variational approach for picking optimal surfaces from semblance-like panels |
As a natural extension of the one-dimensional functional of Fomel (2009) (Equation 2) to higher dimensions, consider the functional
![]() is a semblance-like volume over spatial domain
is a semblance-like volume over spatial domain ![]() .
. ![]() and
and ![]() are regularization parameters. Increasing
are regularization parameters. Increasing ![]() makes the minimizing functions more closely follow highs in
makes the minimizing functions more closely follow highs in ![]() , while decreasing it makes the output minimizing functions smoother.
, while decreasing it makes the output minimizing functions smoother. ![]() is a small positive term which penalizes changes in minimizing functions and ensures they exists in
is a small positive term which penalizes changes in minimizing functions and ensures they exists in
![]() (Dobson and Vogel, 1997). Although we found that
(Dobson and Vogel, 1997). Although we found that ![]() may be set to negligibly small values on the order of machine precision in practice, a complete mathematical treatment of this problem, which is beyond the scope of this manuscript but may be found in Chapter 5 of Decker (2021) and draws inspiration from Dacorogna (2004) and Smyrlis and Zisis (2004), shows how the
may be set to negligibly small values on the order of machine precision in practice, a complete mathematical treatment of this problem, which is beyond the scope of this manuscript but may be found in Chapter 5 of Decker (2021) and draws inspiration from Dacorogna (2004) and Smyrlis and Zisis (2004), shows how the ![]() term is essential for guaranteeing the existence of and convergence to minimizers of Equation 4 in an infinite-dimensional setting. Again, larger values of
term is essential for guaranteeing the existence of and convergence to minimizers of Equation 4 in an infinite-dimensional setting. Again, larger values of ![]() lead to minimizing surfaces which may vary significantly to follow high values of
lead to minimizing surfaces which may vary significantly to follow high values of ![]() more closely. Larger values of
more closely. Larger values of ![]() ensure that minimizing surfaces have less total variation. The examples in this paper use
ensure that minimizing surfaces have less total variation. The examples in this paper use
![]() and
and
![]() .
.
Minimizing surfaces of Equation 4 occur when its Fréchet derivative, defined as
Directly determining minimizing surfaces involves solving a nonlinear elliptic partial differential equation, which can be challenging. Instead, we choose to adopt an iterative approach by introducing a pseudo-time coordinate, ![]() , and solving the parabolic equation
, and solving the parabolic equation
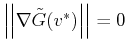 . This is a common approach for finding the minima of a functional (Mawhin and Willem, 2010) and suggests the use of an iterative gradient descent scheme. This method provides a sequence
. This is a common approach for finding the minima of a functional (Mawhin and Willem, 2010) and suggests the use of an iterative gradient descent scheme. This method provides a sequence
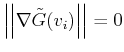 the method stops because it has arrived at a critical point or minimizer. Otherwise,
the method stops because it has arrived at a critical point or minimizer. Otherwise, 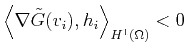 , where
, where
An iterative algorithm for minimizing Equation 4 to pick an optimal surface from a semblance-like volume is implemented in the Madagascar software library (Fomel et al., 2013) using NumPy. Parallelism is achieved using Numba, and NumPy functions are rewritten as simple, array-based, object-free operations and performance tested using Numba on a Texas Advanced Computing Center (TACC) Stampede2 compute node with 48 Skylake cores for code optimization of each component helper function. The Fréchet derivative, or functional gradient
![]() , given by Equation 5 is computed using finite-difference derivative operations and the Numba functions written for the task. The finite-difference approach was chosen for numerical efficiency. Representing the large, semblance-like panels that are used for
, given by Equation 5 is computed using finite-difference derivative operations and the Numba functions written for the task. The finite-difference approach was chosen for numerical efficiency. Representing the large, semblance-like panels that are used for
![]() as FEniCS interpolated functions for finite element implementation was found to be overly expensive, and finite-difference computations yielded satisfactory results at reduced computational cost. The calculated gradient is utilized with the
as FEniCS interpolated functions for finite element implementation was found to be overly expensive, and finite-difference computations yielded satisfactory results at reduced computational cost. The calculated gradient is utilized with the ![]() -BFGS two-loop recursion method outlined by Nocedal (1980) for approximating the inverse Hessian and calculating a search direction. After experimentation on different data sets, we found that a memory size of the past 3 gradient computations for use in the approximation of the inverse Hessian achieved the most rapid cost convergence results. The step size is determined using the output search direction with a golden-section search (Mordecai and Wilde, 1966; Kiefer, 1953). The method is allowed to iterate and update the model until either a maximum number of iterations are achieved, any step size in the search direction fails to decrease the cost by more than a set amount, or the
-BFGS two-loop recursion method outlined by Nocedal (1980) for approximating the inverse Hessian and calculating a search direction. After experimentation on different data sets, we found that a memory size of the past 3 gradient computations for use in the approximation of the inverse Hessian achieved the most rapid cost convergence results. The step size is determined using the output search direction with a golden-section search (Mordecai and Wilde, 1966; Kiefer, 1953). The method is allowed to iterate and update the model until either a maximum number of iterations are achieved, any step size in the search direction fails to decrease the cost by more than a set amount, or the ![]() magnitude of the calculated gradient drops below a threshold. We also found that the Hessian may change rapidly in this problem, leading some search directions output by the
magnitude of the calculated gradient drops below a threshold. We also found that the Hessian may change rapidly in this problem, leading some search directions output by the ![]() -BFGS scheme to increase the cost of surfaces for all step sizes. In this circumstance, the previous gradient computations are ``forgotten'' and the
-BFGS scheme to increase the cost of surfaces for all step sizes. In this circumstance, the previous gradient computations are ``forgotten'' and the ![]() -BFGS algorithm is reset, enabling a fresh approximation of the inverse Hessian. Careful readers will also notice a dimensional analysis ambiguity when calculating best-fit surfaces from typical semblance panels using the Fréchet derivative defined in Equation 5. Usually, the first axis in these data is seismic trace recording time, while other axes are spatial with units of distance. In order to convert derivatives in these different units into similar ones, spatial derivatives are multiplied by the velocity model for the previous iteration so they have units of s
-BFGS algorithm is reset, enabling a fresh approximation of the inverse Hessian. Careful readers will also notice a dimensional analysis ambiguity when calculating best-fit surfaces from typical semblance panels using the Fréchet derivative defined in Equation 5. Usually, the first axis in these data is seismic trace recording time, while other axes are spatial with units of distance. In order to convert derivatives in these different units into similar ones, spatial derivatives are multiplied by the velocity model for the previous iteration so they have units of s![]() .
.
Convergence of this algorithm requires at least local convexity (Li and Fukushima, 2001; Nocedal, 1980; Dennis and Moré, 1977), which is achieved by enforcing smoothness on
![]() using triangle smoothing filters (Claerbout, 1993). As a practical point, artificially large values in
using triangle smoothing filters (Claerbout, 1993). As a practical point, artificially large values in
![]() not related to high-quality fit for the parameter being tested must be muted to prevent them from capturing the cost minimizing surface. In this paper, we manually define muting functions.
not related to high-quality fit for the parameter being tested must be muted to prevent them from capturing the cost minimizing surface. In this paper, we manually define muting functions.
Convergence can only be guaranteed to a local minimizer. For a unique minimizer to exist, the integrand of Equation 4 would need to be strictly convex in every ![]() ,
, ![]() combination for all
combination for all
![]() (Dacorogna, 2004), which places unrealistic burdens on
(Dacorogna, 2004), which places unrealistic burdens on ![]() . In order to overcome the multimodality of this problem, we employ continuation, or graduated optimization. This involves smoothing and scaling the semblance-like volume several times. Smoothing makes the semblance volume more convex, and scaling increases the attraction of semblance highs for
. In order to overcome the multimodality of this problem, we employ continuation, or graduated optimization. This involves smoothing and scaling the semblance-like volume several times. Smoothing makes the semblance volume more convex, and scaling increases the attraction of semblance highs for
![]() surfaces. If sufficiently strong smoothing is applied, the problem may become convex (Hazan et al., 2016). In this paper, the authors choose a set of minimum smoothing radii that capture the finest scale of changes in the semblance-like volume that appear to be representative of the underlying model. The maximum smoothing radii are determined by multiplying the minimum radii by a sufficiently large number so that smoothing makes panels of the semblance volume appear strictly convex. We choose a number of smoothing levels, then proceed incrementally from maximum to minimum smoothing in a linear manner. The semblance scaling factor for each level is chosen to be proportional to the ratio between smoothing at that level and minimum smoothing. A constant-gradient velocity field is used as the starting model on the most-smoothed semblance volume, and the minimizing velocity surface is iteratively determined using the two-loop recursion
surfaces. If sufficiently strong smoothing is applied, the problem may become convex (Hazan et al., 2016). In this paper, the authors choose a set of minimum smoothing radii that capture the finest scale of changes in the semblance-like volume that appear to be representative of the underlying model. The maximum smoothing radii are determined by multiplying the minimum radii by a sufficiently large number so that smoothing makes panels of the semblance volume appear strictly convex. We choose a number of smoothing levels, then proceed incrementally from maximum to minimum smoothing in a linear manner. The semblance scaling factor for each level is chosen to be proportional to the ratio between smoothing at that level and minimum smoothing. A constant-gradient velocity field is used as the starting model on the most-smoothed semblance volume, and the minimizing velocity surface is iteratively determined using the two-loop recursion ![]() -BFGS scheme until convergence on that model is achieved. The minimizing surface from one level of smoothing is then used as the starting model on the next-less-smoothed semblance volume. The method proceeds until finding the cost minimizing velocity on the least-smoothed model. Because the method is allowed to operate on semblance-like volumes with different levels of smoothing, it is able to find the macro-trends for the best-fit surface before determining finer components. This enables the method to behave more like a global optimizer and enjoy applicability to problems beyond picking velocity surfaces from semblance-like volumes as experiments in subsequent sections illustrate.
-BFGS scheme until convergence on that model is achieved. The minimizing surface from one level of smoothing is then used as the starting model on the next-less-smoothed semblance volume. The method proceeds until finding the cost minimizing velocity on the least-smoothed model. Because the method is allowed to operate on semblance-like volumes with different levels of smoothing, it is able to find the macro-trends for the best-fit surface before determining finer components. This enables the method to behave more like a global optimizer and enjoy applicability to problems beyond picking velocity surfaces from semblance-like volumes as experiments in subsequent sections illustrate.
|
|
|
|
A variational approach for picking optimal surfaces from semblance-like panels |
![$\displaystyle \tilde{G}[v] = \int_\Omega e^{-\alpha[v(\mathbf{x}),\mathbf{x}]}\...
...\vert^2} + \frac{\epsilon}{2} \left\vert \nabla v \right\vert^2 \right)d\Omega.$](img20.png)
![\begin{displaymath}\begin{split}\nabla \tilde{G}(v) =& -\alpha_v[v(\mathbf{x}),\...
... v\right\vert^2}}+\epsilon \right]\nabla v \right), \end{split}\end{displaymath}](img46.png)