|
|
|
|
Random noise attenuation by |
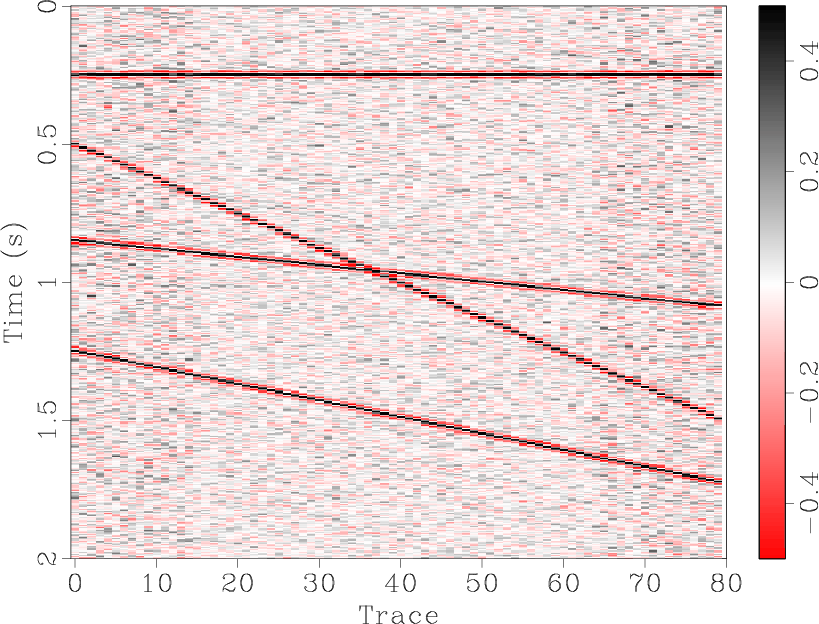
![]() predictive filtering works perfectly on a single event. Figures 1(a)-1(c) show and compare the denoised results for a single flat synthetic event. The denoised result (Figure 1(b)) is quite good, with the random noise in Figure 1(a) largely removed and only a small amount of the useful component in the noise section, Figure 1(c). For a single dipping event, Figures 1(d)-1(f), the results are similar. However, when the number of different dips is increased, the seismic section becomes more complex and predictive filtering is not as effective. Figure 1(j) shows a synthetic section containing four events with differing dips. In the removed noise section, Figure 1(i), there remains a significant amount of residual useful energy.
predictive filtering works perfectly on a single event. Figures 1(a)-1(c) show and compare the denoised results for a single flat synthetic event. The denoised result (Figure 1(b)) is quite good, with the random noise in Figure 1(a) largely removed and only a small amount of the useful component in the noise section, Figure 1(c). For a single dipping event, Figures 1(d)-1(f), the results are similar. However, when the number of different dips is increased, the seismic section becomes more complex and predictive filtering is not as effective. Figure 1(j) shows a synthetic section containing four events with differing dips. In the removed noise section, Figure 1(i), there remains a significant amount of residual useful energy.
The synthetic data shown in Figures 1(a), 1(d), and 1(j) were all generated by SeismicLab (Sacchi, 2008), with a signal-to-noise ratio (SNR) of 2.0 for all of them. Here we define the SNR as the ratio of maximum amplitude of useful energy and the maximum amplitude of Gaussian white noise. Note that the same parameters were used for the predictive filters in each case shown in Figure 1.
We now conclude that the effectiveness of ![]() predictive filtering deteriorates as the number of different dips increases, mainly because the total of leaked useful energy increases at the same time. In particular, when the number of dips is extremely large, as occurs with hyperbolic events,
predictive filtering deteriorates as the number of different dips increases, mainly because the total of leaked useful energy increases at the same time. In particular, when the number of dips is extremely large, as occurs with hyperbolic events, ![]() predictive filtering fails to achieve acceptable results. It is natural to infer that if we can first reduce the number of dips, or in other words pick the very steep events and total random noise out, then by applying the same
predictive filtering fails to achieve acceptable results. It is natural to infer that if we can first reduce the number of dips, or in other words pick the very steep events and total random noise out, then by applying the same ![]() predictive filtering, the predictive precision will improve. That is the subject of the section on
predictive filtering, the predictive precision will improve. That is the subject of the section on ![]() empirical mode decomposition predictive filtering.
empirical mode decomposition predictive filtering.










|
|---|
|
syn01-flat,syn01-flat-fxdecon,syn01-flat-fxdecon-noise,syn01-dip,syn01-dip-fxdecon,syn01-dip-fxdecon-noise,syn01-complex,syn01-complex-fxdecon,syn01-complex-fxdecon-noise,syn01-complex,syn01-complex-fxemdpf,syn01-complex-fxemdpf-noise
Figure 1. Demonstration of |
|
|
|
|
|
|
Random noise attenuation by |