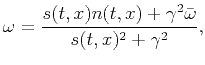|
|
|
|
Streaming orthogonal prediction filter in |
Consider a 2D noncausal prediction filter with 20 prediction
coefficients ![]() :
:
The least-squares solution of equation 1 is
Fomel and Claerbout (2016) propose the Sherman-Morrison formula to directly
transform the inverse matrix in equation 4 without
iterations. The Sherman-Morrison formula is an analytic method for
solving the inverse of a special matrix (Hager, 1989). If both
matrices
![]() and
and
![]() are invertible, then
are invertible, then
![]() is invertible and
is invertible and
Applying the Sherman-Morrison formula to
equation 4, the ![]() -
-![]() streaming PF coefficients and
prediction error can be calculated as
streaming PF coefficients and
prediction error can be calculated as
For seismic random noise attenuation, we assume the residual of
prediction filtering ![]() is the random noise at the point
is the random noise at the point
![]() . For calculating 2D
. For calculating 2D ![]() -
-![]() streaming PFs, we need to store
one previous time-neighboring PF,
streaming PFs, we need to store
one previous time-neighboring PF,
![]() , and
one previous space-neighboring PF,
, and
one previous space-neighboring PF,
![]() , both
, both
![]() and
and
![]() will be used when the stream arrives at its
adjacency.
will be used when the stream arrives at its
adjacency.
One can compare a streaming PF with a stationary PF. The autoregression equation for a traditional PF takes the following form:
The least-squares solution of equation 10 at each point ![]() is
is
The matrix in equation 11 is similar to that in
equation 4. The comparison of equation 4 and
equation 11 indicates that the results of the streaming PFs
become gradually more accurate as the scale parameter ![]() decreases. However, according to equation 9, a small
decreases. However, according to equation 9, a small
![]() may cause the residual
may cause the residual ![]() to also be small, which
means that there is too much noise in the signal section. To solve
this problem, we use a two-step strategy. First, we
choose a relatively large
to also be small, which
means that there is too much noise in the signal section. To solve
this problem, we use a two-step strategy. First, we
choose a relatively large ![]() to get a large residual
to get a large residual
![]() . The first step amounts to an ``over-filtering'', which
generates an approximately ``clean'' signal. Next, the
signal leakage in the noise section can be extracted by applying
signal-and-noise orthogonalization.
. The first step amounts to an ``over-filtering'', which
generates an approximately ``clean'' signal. Next, the
signal leakage in the noise section can be extracted by applying
signal-and-noise orthogonalization.
We derive the definition of the streaming orthogonalization
weight (SOW) from the global orthogonalization weight (GOW)
(Chen and Fomel, 2015). Assume that the leaking signal
![]() has a
linear correlation with the estimated signal section
has a
linear correlation with the estimated signal section
![]() in
the first step,
in
the first step,
Substituting equation 13 and 14 into equation 15, one can get the GOW as
To get the orthogonalization weight for each data value, one possible definition of the SOW is:
Suppose that the SOW gets updated with each new data point
![]() . The new SOW,
. The new SOW, ![]() , should stay close to the previous
time-neighboring SOW
, should stay close to the previous
time-neighboring SOW
![]() and the previous
space-neighboring SOW
and the previous
space-neighboring SOW
![]() . Equation 17 can be
rewritten as
. Equation 17 can be
rewritten as
The least-squares solution of equation 18 is
Applying equation 13, one can get the denoised data value
![]() after the SOPF
after the SOPF
We implement the two-step strategy within the streaming
method and obtain the denoised data value as each
new noisy data value arrives. Table 1 compares the computational cost
between ![]() -
-![]() deconvolution,
deconvolution, ![]() -
-![]() regularized
nonstationary autoregression (RNA) (Liu et al., 2012), and the proposed
method. In general, the cost of SOPF is minimal.
regularized
nonstationary autoregression (RNA) (Liu et al., 2012), and the proposed
method. In general, the cost of SOPF is minimal.
| Method | Filter storage | Cost |
|
|
||
|
|
|
|
|
|
|
|
|
|
|
Streaming orthogonal prediction filter in |
![$\displaystyle \left[ \begin{array}{c} \mathbf{d}^T\\ \lambda_t \mathbf{I}\\ \la...
...\lambda_t \mathbf{\bar{a}}_t\\ \lambda_x \mathbf{\bar{a}}_x \end{array}\right],$](img16.png)
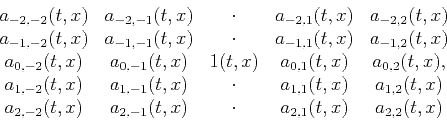
![$\displaystyle \mathbf{d}=\left[ \begin{array}{c} d_{-M,-N}(t,x)\\ d_{-M+1,-N}(t...
...\ a_{-M+1,-N}(t,x)\\ \ldots\\ a_{M-1,N}(t,x)\\ a_{M,N}(t,x) \end{array}\right],$](img26.png)






![$\displaystyle \left[ \begin{array}{c} s(t,x)\\ \gamma_t\\ \gamma_x \end{array}\...
...c} n(t,x)\\ \gamma_t\bar{\omega}_t\\ \gamma_x\bar{\omega}_x \end{array}\right],$](img70.png)