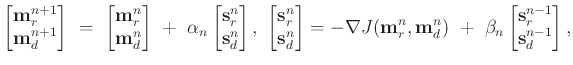|
|
|
|
Least-squares path-summation diffraction imaging using sparsity constraints |
Next: Regularization Up: Method Previous: Objective function
|
|
|
|
Least-squares path-summation diffraction imaging using sparsity constraints |
To solve the optimization problem in equations 6, 8, 9 we employ a conjugate-gradients scheme:
It is important to highlight that the same operator is used to update both images of reflections
![]() and
diffractions
and
diffractions
![]() . The implication of this strategy is that without regularization same updates are attributed to both models. For simplicity, consider conjugate direction
. The implication of this strategy is that without regularization same updates are attributed to both models. For simplicity, consider conjugate direction
![]() at the zero iteration
at the zero iteration ![]() . It has the form of
. It has the form of
![]() (PWD (
(PWD (
![]() ) and path-summation integral (
) and path-summation integral (
![]() ) are disabled for objective functions in equations 8, 9 correspondingly), where
) are disabled for objective functions in equations 8, 9 correspondingly), where
![]() corresponds to the residual between the observed data
corresponds to the residual between the observed data
![]() and the data modeled from the initial guess model
and the data modeled from the initial guess model
![]() (initialized by zeroes for the first inversion (equation 6)
and by the output of the first inversion (equation 6) for optimization of the objective function in equation 8).
The conjugate direction
(initialized by zeroes for the first inversion (equation 6)
and by the output of the first inversion (equation 6) for optimization of the objective function in equation 8).
The conjugate direction
![]() is equal to the negative gradient of the objective function
is equal to the negative gradient of the objective function
![]() .
It is obvious that the residual
.
It is obvious that the residual
![]() in the conjugate direction
in the conjugate direction
![]() is mapped to reflection and diffraction image using the same operator - the
adjoint of the “chain”. The same is true for all of the iterations. In this case, previous directions
is mapped to reflection and diffraction image using the same operator - the
adjoint of the “chain”. The same is true for all of the iterations. In this case, previous directions
![]() , which are also the same for both models, participate in the update. To perform reflection and diffraction
separation regularization is required.
, which are also the same for both models, participate in the update. To perform reflection and diffraction
separation regularization is required.
|
|
|
|
Least-squares path-summation diffraction imaging using sparsity constraints |